Created: 2026-03-06 07:53:04
Updated: 2026-03-06 07:53:04
对于一个没有限制的、取值为全体正整数的离散随机变量X,考虑一下两个问题:
(无上界)是否存在一个X n X_{n} X n lim n → ∞ ∣ H ( X n ) ∣ = ∞ \lim_{ n \to \infty } \mid H(X_{n})\mid = \infty lim n → ∞ ∣ H ( X n ) ∣= ∞
是否存在一个分布使得H ( X ) = ∞ H(X)=\infty H ( X ) = ∞
二者的答案均为肯定的。第一个的存在性是显然的,对于第二个,下面我们可以证明,p ( n ) ∼ 1 n ln 2 n p(n)\sim \frac{1}{n\ln^2 n} p ( n ) ∼ n l n 2 n 1
∑ n = 1 ∞ p ( n ) ∼ ∑ n = 1 ∞ 1 n ln 2 n ∼ ∫ 1 ∞ 1 x ln 2 x d x = Const ∑ n = 1 ∞ p ( n ) ln p ( n ) ∼ ∑ n 1 n ln 2 n ln 1 n ln 2 n = ∑ n − ln n − 2 ln ln n n ln 2 n ∼ ∑ n − 1 n ln n ∼ ∫ 1 ∞ − 1 x ln x d x → − ∞ \begin{align}
\sum_{n=1}^\infty p(n) & \sim \sum_{n=1}^\infty \frac{1}{n\ln^2n}\sim \int _{1}^\infty \frac{1}{x\ln^2x}\, dx = \text{Const} \\
\sum_{n=1}^\infty p(n) \ln p(n) & \sim \sum_{n} \frac{1}{n\ln^2n} \ln \frac{1}{n\ln^2n} \\
& = \sum_{n} \frac{-\ln n-2\ln \ln n}{n\ln^2n} \\
& \sim \sum_{n} -\frac{1}{n\ln n} \\
& \sim \int _{1}^\infty -\frac{1}{x\ln x} \, dx \to -\infty
\end{align} n = 1 ∑ ∞ p ( n ) n = 1 ∑ ∞ p ( n ) ln p ( n ) ∼ n = 1 ∑ ∞ n ln 2 n 1 ∼ ∫ 1 ∞ x ln 2 x 1 d x = Const ∼ n ∑ n ln 2 n 1 ln n ln 2 n 1 = n ∑ n ln 2 n − ln n − 2 ln ln n ∼ n ∑ − n ln n 1 ∼ ∫ 1 ∞ − x ln x 1 d x → − ∞
式子中∼ \sim ∼ Cauchy积分判别法 :
[!theorem] Cauchy判别法[ 0 , ∞ ) [0,\infty ) [ 0 , ∞ ) f ( x ) f(x) f ( x ) ∑ n = 1 ∞ f ( n ) \sum_{n=1}^\infty f(n) ∑ n = 1 ∞ f ( n ) ∫ 1 ∞ f ( x ) d x \int _{1}^\infty f(x)\, dx ∫ 1 ∞ f ( x ) d x
现考虑约束:随机变量具有均值μ \mu μ
p i ∼ C e − λ i p_{i} \sim Ce^{-\lambda i} p i ∼ C e − λi
对于任意的其他分布g i g_{i} g i
H ( g ∣ ∣ p ) = H ( g ) − H ( p ) ≥ 0 H(g\mid \mid p) = H(g)-H(p) \geq 0 H ( g ∣∣ p ) = H ( g ) − H ( p ) ≥ 0
即指数分布是该约束下的最大熵分布。
Lecture 9: Fisher Information and Cramer-Ral Inequality
概率统计中常见到Parameter Estimation问题。对于参数估计的好坏有一些准则,例如无偏性X = ( X 1 , … , X n ) X=(X_{1},\dots,X_{n}) X = ( X 1 , … , X n ) X X X f ( X ; θ ) = ∏ i = 1 n f ( X i ; θ ) f(X;\theta) = \prod_{i=1}^n f(X_{i};\theta) f ( X ; θ ) = ∏ i = 1 n f ( X i ; θ ) θ \theta θ ϕ : X → θ \phi:X\to\theta ϕ : X → θ E [ ϕ ( X ) ] = θ E[\phi(X)] = \theta E [ ϕ ( X )] = θ
Fisher Information
[!definition] Scure functionX = ( X 1 , … , X n ) X=(X_{1},\dots,X_{n}) X = ( X 1 , … , X n ) f ( ⋅ , 0 ) f(\cdot,0) f ( ⋅ , 0 )
容易证明E [ S ( X ; θ ) ] = 0 E[S(X;\theta)] = 0 E [ S ( X ; θ )] = 0
\fcolorbox{yellow}{}{Proof}
E S = ∫ f ( x , θ ) S ( X , θ ) d x = ∫ ∂ ∂ θ f ( x , θ ) d x = ∂ ∂ θ ∫ f ( x , θ ) d x = 0 \begin{align}
\mathbb{E} S & = \int f(x,\theta) S(X,\theta) \, dx \\
& = \int \frac{ \partial }{ \partial \theta } f(x,\theta) \, dx \\
& = \frac{ \partial }{ \partial \theta } \int f(x,\theta) \, dx \\
& = 0
\end{align} E S = ∫ f ( x , θ ) S ( X , θ ) d x = ∫ ∂ θ ∂ f ( x , θ ) d x = ∂ θ ∂ ∫ f ( x , θ ) d x = 0
[!definition] Fisher informationθ \theta θ X X X
容易证明:I ( θ ) = − E [ ∂ 2 ln f ( X ; θ ) ∂ θ 2 ] I(\theta) = -E\left[ \frac{ \partial ^2 \ln f(X;\theta) }{ \partial \theta^2 } \right] I ( θ ) = − E [ ∂ θ 2 ∂ 2 l n f ( X ; θ ) ]
[!theorem] Cramer-Rao Inequalityϕ : X → R \phi: X\to \mathbb{R} ϕ : X → R θ j \theta_{j} θ j V a r ( ϕ ( X ) ) ≥ 1 I ( θ ) Var(\phi(X))\geq \frac{1}{I(\theta)} Va r ( ϕ ( X )) ≥ I ( θ ) 1
[!Proof]V a r ( ϕ ( X ) ) V a r ( S ( X ; θ ) ) ≥ 1 Var(\phi(X)) Var (S(X;\theta)) \geq 1 Va r ( ϕ ( X )) Va r ( S ( X ; θ )) ≥ 1 ( u , v ) = ∑ i u ( x i ) v ( x i ) f ( x i ) (u,v) = \sum_{i} u(x_{i})v(x_{i})f(x_{i}) ( u , v ) = ∑ i u ( x i ) v ( x i ) f ( x i ) ( u , u ) ( v , v ) ≥ ∣ ( u , v ) ∣ 2 (u,u)(v,v)\geq \mid(u,v) \mid^2 ( u , u ) ( v , v ) ≥∣ ( u , v ) ∣ 2
Fisher information for multiple parameters:
S ⃗ ( X ; θ ⃗ ) = ∇ θ ln f ( X ; θ ⃗ ) \vec{S}(X;\vec{\theta}) = \nabla_{\theta} \ln f(X;\vec{\theta}) S ( X ; θ ) = ∇ θ ln f ( X ; θ )
易证明E ( S ( X ; θ ⃗ ) ) = 0 ⃗ E(S(X;\vec{\theta})) = \vec{0} E ( S ( X ; θ )) = 0
I ( θ ⃗ ) = E [ S ⃗ ( X ; θ ⃗ ) S ( ⃗ X ; θ ⃗ ) T ] = C o v ( S ⃗ ( X ; θ ⃗ ) ) I(\vec{\theta}) = E[\vec{S}(X;\vec{\theta}) S(\vec{}X;\vec{\theta})^T] = Cov(\vec{S}(X;\vec{\theta})) I ( θ ) = E [ S ( X ; θ ) S ( X ; θ ) T ] = C o v ( S ( X ; θ ))
高维情形下,Fisher Information的二阶导数写法可换为函数的Hessian Matrix:
I ( θ ⃗ ) = − E [ ∇ 2 ln f ( X ; θ ) ] I(\vec{\theta}) = -E \left[\nabla ^2 \ln f(X;\theta)\right] I ( θ ) = − E [ ∇ 2 ln f ( X ; θ ) ]
协方差矩阵为C o v ( ϕ ( X ) ) Cov(\phi(X)) C o v ( ϕ ( X ))
C o v ( ϕ ( X ) ) ≥ I ( θ ) − 1 Cov(\phi(X)) \geq I(\theta)^{-1} C o v ( ϕ ( X )) ≥ I ( θ ) − 1
其中≥ \geq ≥ A , B A,B A , B A ≥ B ⟹ A − B ≥ 0 A\geq B\implies A-B\geq 0 A ≥ B ⟹ A − B ≥ 0 A − B A-B A − B
4.18 Channel Coding
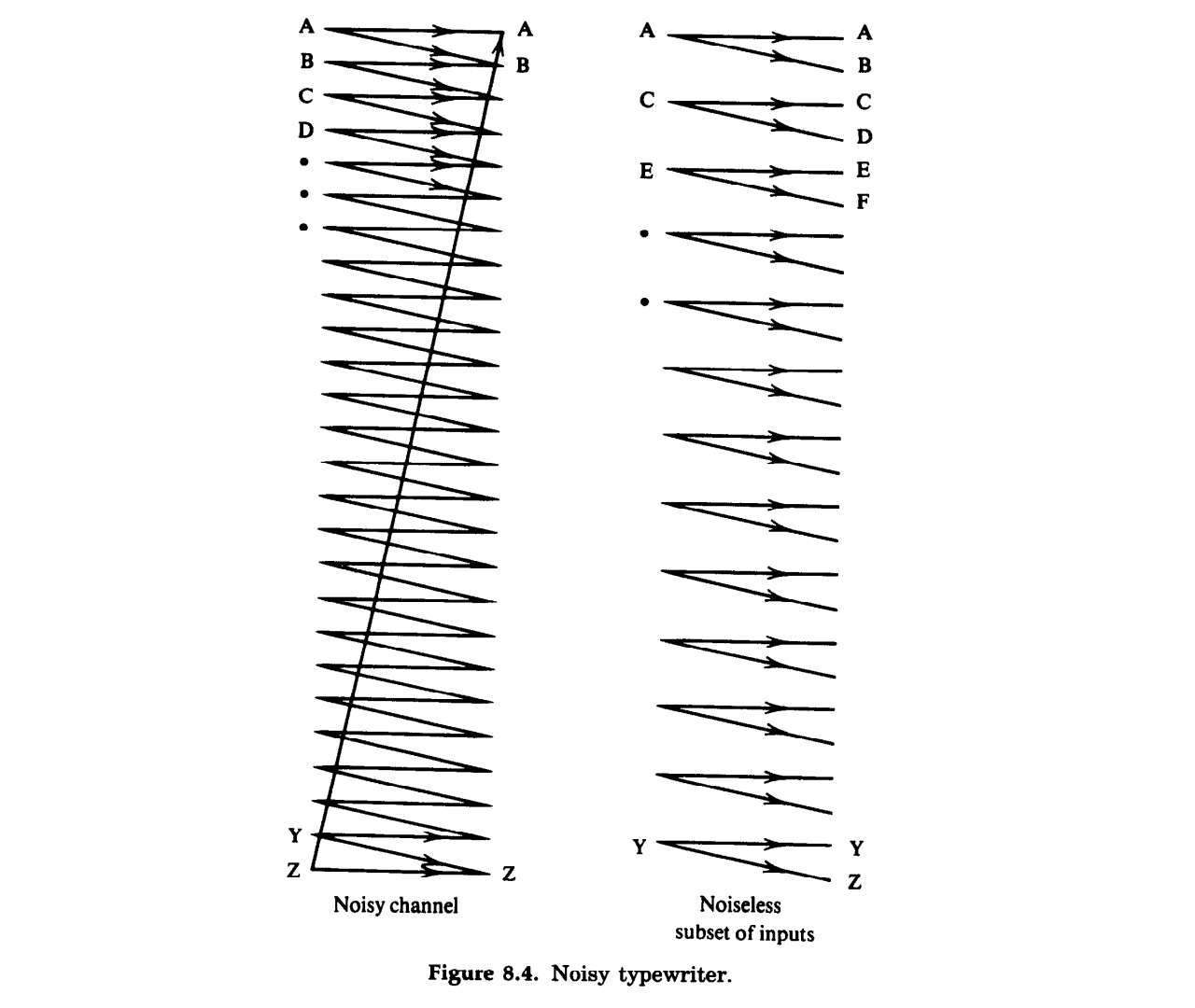
信源编码目标是将码元中的冗余去除;而在信道传输时信道会引入噪声,从而有一定概率发生错误。信道编码目标是通过高度结构化的方式加入冗余,使编码之间的距离尽可能大。t t t 2 t + 1 2t+1 2 t + 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a Comment