Created: 2026-03-06 07:53:04
Updated: 2026-03-06 07:53:04
(选)
D-adic: 一个概率分布被称为D-adic的,如果每个概率值都是D−n,n为正整数
对于任意编码对应的码长li,随机变量X,都有平均码长大于等于随机变量X对应的熵:
L≡i∑pili≥HD(X)
上式等号成立当且仅当编码是D−adic的,此时各个li=logpi1才能为整数
5.4 Bounds on the optimal codelength
定理:对于任意的概率分布,我们总能找到一组编码使得其平均码长比下界高出1bit之内,即
H(X)≤L<H(X)+1
证明只需取li=⌈logD(pi1)⌉,证明它满足Kraft不等式(显然)。由于向上取整满足xi≤⌈xi⌉≤xi+1,经过概率加权后即证明满足关系H(X)≤L≤H(X)+1
对于Optimal Code,它的平均码长L∗也满足这个关系。由定义知道L∗<L,同时又有L∗≥H(X),因此得证。
我们已经证明了,传输单个符号最多多用一个比特。对于同时传输多个随机变量X的符号的情况,我们还能找到一个更低的下界。
定义Ln为传输来自随机变量X的n个符号的平均码长,即
Ln=n1∑p(x1,x2,…,xn)l(x1,x2,…,xn)=n1El(X1,X2,…,Xn)
我们可以将之前的定理用在这里:
H(X1,X2,…,Xn)≤El(X1,X2,…,Xn)<H(X1,X2,…,Xn)+1
由于各个Xi都是来自X的独立同分布随机变量,于是H(X1,…,Xn)=nH(X),就得到
H(X)≤Ln<H(X)+n1
因此,如果使用更长的块来传输,我们可以将最短平均码长的上限降低到无限接近最优码长。
同样地,不作独立同分布的假设,Xi之间就构成了随机过程,于是有
nH(X1,…,Xn)≤Ln<nH(X1,…,Xn)+n1
Huffman Codes和Slice Codes
Slice Codes:对于来自一个概率分布的随机变量X,slice code这种编码中每一个bit可以把所有可能分成两部分:{x:x>a},{x:x<a}。Huffman Code不一定能满足这个性质。
Alphabetic codes: 码元是按顺序排列的编码
Using codeword lengths of ⌈logpi1⌉ can be much worse than the optimal code for some particular symbol. For example, consider two symbols with probability 0.9999,0.0001. Then using codeword lengths of ⌈logpi1⌉ means 1bit and 14bits respectively.
Is it true that the codeword lengths for an optimal code are always less than ⌈logpi1⌉ ? The following example illustrates that this is not always true.
distribution:(31,31,41,121)
Huffman coding: (2,2,2,2) or (1,2,3,3)
第一个码元长度为:1<−log31,矛盾。这个例子还说明optimal code的码元长度不一定唯一。
Fano Codes:是一种suboptimal procedure,得到的结果是alphabetic的。
方式:不断进行二分。将所有可能按概率降序排列。之后取k使得前k个概率之和与后面的概率之和之差的绝对值∣∑i=1kpi−∑i=k+1mpi∣最小。给前面集合分配0,后面的分配1,然后重复这个操作。这样可以使得平均码长L(C)≤H(X)+2
5.11 Competitive optimality of the Shannon Code
对于一些特定的符号,哈夫曼码/香农码相比其他码长而言不一定能做的更好,因为其他编码中概率低的符号可能有更短的码长,这时就比哈夫曼编码/香农码更长的码长要好。但这种情形出现的概率是多少?为了方便起见,我们使用香农码来进行研究,因为它具有固定的码长l(x)=⌈logp(x)1⌉。
Theorem 5.11.1: l(x)为香农码码长,l′(x)是其他编码码长,则
Pr(l(X)≥l′(X)+c)≤2c−11
Proof:
Pr(l(X))≥l′(X)+c)=Pr(⌈logp(X)1⌉≥l′(X)+c)≤Pr(logp(X)1≥l′(X)+c−1)=Pr(p(X)≤2−l′(X)−c+1)=x:p(x)≤2−l′(x)−c+1∑p(x)≤x:p(x)≤2−l′(x)−c+1∑2−l′(x)−(c−1)≤x∑2−l′(x)2−(c−1)≤2−(c−1)
然而,我们更多时候期望l(x)<l′(x)多于l(x)>l′(x),而不是l(x)≤l′(x)+1。可以证明,即便在更严格的情形下Shannon Coding依然是最优的。
Theorem 5.11.2: 对于一个dyadic的分布函数p(x)(即概率分布数值满足logp(x)1为整数),l(x)=logp(x)1为香农码的码长,l′(x)为任意唯一可译编码码长,则
Pr(l(X)≤l′(X))≥Pr(l(X)>l′(X))
取等当且仅当l′(x)=l(x),∀x,因此编码长度l(x)=logp(x)1是唯一且competitively最优的
5.12 Generation of Distributions from Fair Coins
这一节中我们考虑一个不一样的问题:通过投一枚均匀硬币生成一个给定的离散随机变量的概率分布,现问:需要几次投掷可以生成这样的概率分布?
例如,有随机变量有如下分布:(a,1/2; b,1/4; c,1/4),那么可以通过最多两次投币实现:第一次若为0,则X=a;若为1则投掷第二次:若为0则X=b;若为1则X=c
平均而言我们需要投掷1.5次硬币,这恰好是这个概率分布的熵。
推广这个问题:给定一个投掷硬币的序列,希望用它生成一个随机变量X∈H={1,…,m},具有概率分布(p1,…,pm)。
对于一个分布,通常有不同的对应方式来实现,但有些实现不高效,即需要的平均硬币投掷次数更多。
Theorem 5.12.1 对任意生成随机变量X的算法,期望使用的比特数大于等于X的熵:
ET≥H(X)
对于一个dyadic distribution,可以取得等号。
当分布不是dyadic的该怎么办呢?对于概率pi,写出它的二进制展开,将其分割为更小的原子:
pi=j≥1∑pi(j)
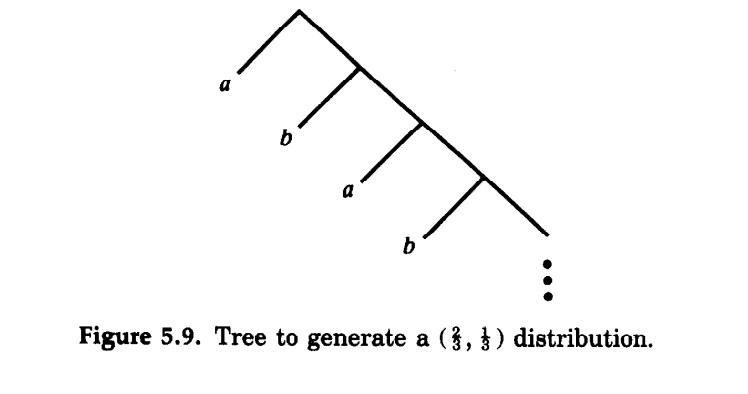
pi(j)=2−j or 0,我们可以在二叉树上给每一个原子安排一个合适的叶节点。举例说明:
X={abwith prob=32,with prob=31
可以找到31和32的二进制展开:
32→(21,81,321,…)31→(41,161,641,…)
从而可以产生这样一棵树:
![[src/Pasted image 20230409111638.png]]
这样的作法是最优的。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave a Comment